<1GB Models - Test 1
MODELS:
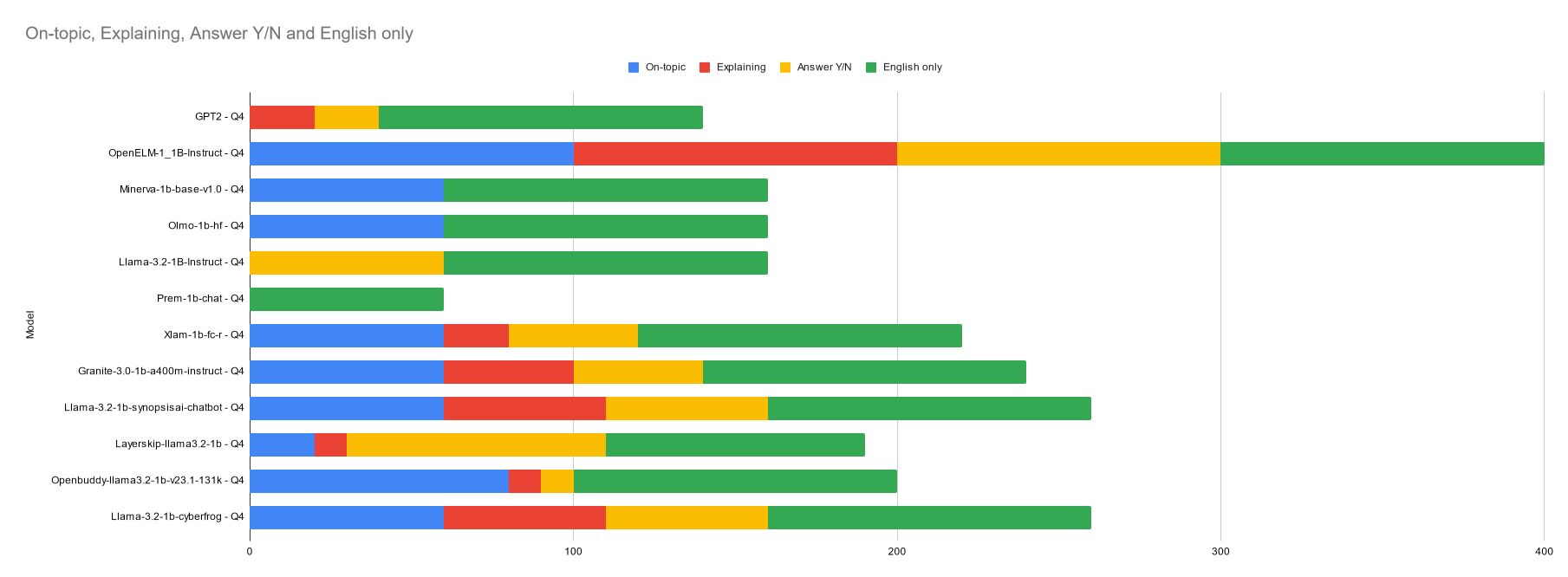
GPT2 - Q4
OpenELM-1_1B-Instruct - Q4
Minerva-1b-base-v1.0 - Q4
Olmo-1b-hf - Q4
Llama-3.2-1B-Instruct - Q4
Prem-1b-chat - Q4
Xlam-1b-fc-r - Q4
Granite-3.0-1b-a400m-instruct - Q4
Llama-3.2-1b-synopsisai-chatbot - Q4
Layerskip-llama3.2-1b - Q4
Openbuddy-llama3.2-1b-v23.1-131k - Q4
Llama-3.2-1b-cyberfrog - Q4
These models were all found on HuggingFace by searching for "q4 gguf 1b". GPT2-Q4 was searched for directly on huggingface to find something very low quality to serve as a minimum baseline that everything else should be able to beat.
These models are all under 1GB in filesize - most being around 800MB, and gpt-2 being a little over 100MB. This is deliberate, to reduce the cpu and memory demands, only small lightweight models were chosen. The assumption is that anything larger or slower would interfere with a videogame.
They all seem around the same speed/cpu usage, aside from GPT2 which is almost instantaneous and doesn't use much cpu. Llama-3.2-1B-Instruct is also slower and uses more cpu.
They have all been quantized to a lower filesize, Q4 meaning 4 bits per weight, as opposed to what is normally 32 bits per weight. The exact command/prompt used for this test is the following:
llama-cli.exe -m MODEL -p "[Respond with only YES or NO] Your hunger level is 50/100. You see an apple in front of you. Do you eat the apple? " -n 20
The command was run 10 times for each model and the output was evaulated on 4 criteria:
On-topic - answer is about the apple, hunger, eating, etc. when the prompt is simply repeated that does not count.
Explaining - some sort of explanation was given for their decision.
Answer Y/N - answer is clearly (ideally the first word) either YES or NO.
English only - only english-language responses will count. responses including gibberish, bad grammer, other languages, or primarily numbers/symbols do not count.
In my opinion for this test the most important thing is to receive a clear YES or NO, to make a decision. In other words, only the yellow bar in the graph above should matter.
LLM for games
Ranking how well various locally-run LLM models perform as ai agents for videogames
| Status | Released |
| Category | Other |
| Author | douteigami |
More posts
- LLMS building rpg fighters, randomized optionsNov 18, 2024
- What stats do LLMS allocate when building an RPG fighter class character?Nov 17, 2024
- <1GB models - test 3Nov 14, 2024
- <1GB models - test 2Nov 14, 2024