What stats do LLMS allocate when building an RPG fighter class character?
I wanted to see how different models allocate stats for an rpg character. I also wanted to automate the testing, instead of doing it manually like before.
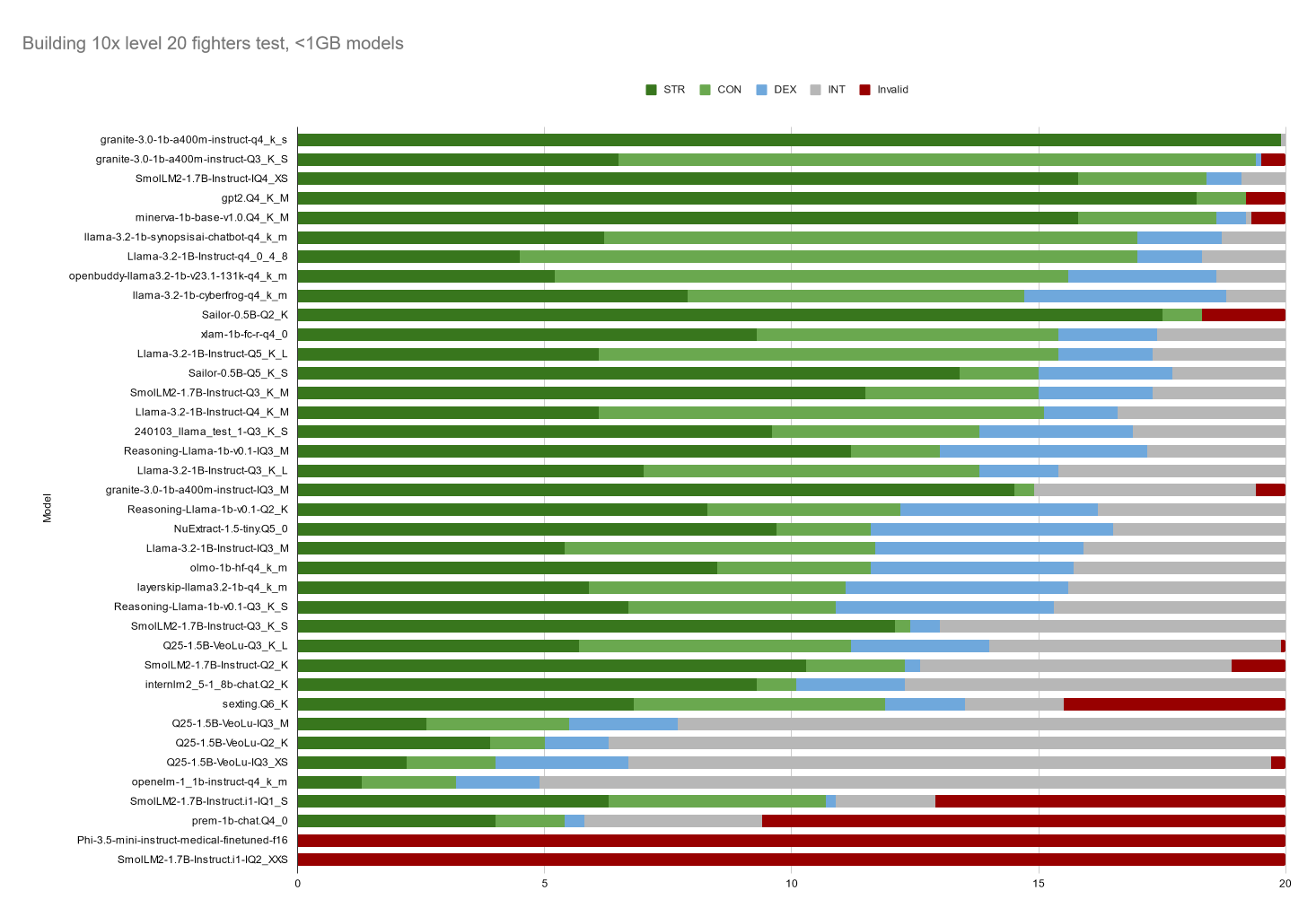
Each model is prompted at every level between 1-20 to allocate stat points between strength, constitution, dexterity, intelligence using A, B, C, or D. They are shown their current level and stats and reminded that their character's class is "Fighter". They allocate points until their character is level 20, and then they do it again, until they have made 10 such characters. The stat allocations for the 10 characters are averaged together.
Points in strength or constitution are added up at face value. Points in dexterity are added at half value. Points in intelligence don't count at all. Invalid input (ie not A B C D) counts as a negative value. Such is how the models were evaluated and sorted based on their performance.
----
I was curious if different quantized versions of the same model perform similarly. If you look at the various SmolLM2 models, ranked in order of best to worst, they go Q4 > Q3 > Q3 > Q2 > Q1 > Q2. If you also just look nonspecifically at anything Q4, they appear mostly at the top, Q3 mid-bottom, and Q2 at the bottom. So this tells me, when confronted with a list of models of all different sizes and Qs, go for the highest Q? I don't see a connection between Q and the speed it takes the model to generate an answer which doesn't make sense to me. I also sometimes see IQ instead of regular Q as well. Not sure what that means yet.
There is also some stuff affixed to the end of model names, after the Q, such as "_K_S" or "_XXS" or "_0_4_8". I don't know what the K means. XXS, XS, S, M, L seem to indicate a size though, perhaps file size? The numbers like "_0_4_8" I have no idea what they might mean.
I wonder if the models would answer the same when the stats are arranged randomly, such that A is not always strength. It might be the case that the models aswering only strength are actually as bad as the models answering only intelligence, but for this test they are lucky that A corresponds to the right answer. This would explain GPT2's performance in this simple test. I think for now the most accurate information you can obtain from this chart is by looking at the invalid scores. Right or wrong answers are both technically valid. Invalid answers are just a waste of time. Any models that cannot provide valid answers for this should be scrutinized, and indeed I find myself always looking at Prem-1B! It probably needs a specific formatted prompt, but that's bad since the other models have no problem with the prompt.
LLM for games
Ranking how well various locally-run LLM models perform as ai agents for videogames
| Status | Released |
| Category | Other |
| Author | douteigami |
More posts
- LLMS building rpg fighters, randomized optionsNov 18, 2024
- <1GB models - test 3Nov 14, 2024
- <1GB models - test 2Nov 14, 2024
- <1GB Models - Test 1Nov 14, 2024
Leave a comment
Log in with itch.io to leave a comment.