<1GB models - test 3
MODELS:
GPT2 - Q4
OpenELM-1_1B-Instruct - Q4
Minerva-1b-base-v1.0 - Q4
Olmo-1b-hf - Q4
Llama-3.2-1B-Instruct - Q4
Prem-1b-chat - Q4
Xlam-1b-fc-r - Q4
Granite-3.0-1b-a400m-instruct - Q4
Llama-3.2-1b-synopsisai-chatbot - Q4
Layerskip-llama3.2-1b - Q4
Openbuddy-llama3.2-1b-v23.1-131k - Q4
Llama-3.2-1b-cyberfrog - Q4
See test 1 for more information about the models and how they are being scored. This test differs in a way I think is better. Whether or not they produce a valid answer/decision is the first criterion. For this test that would be either food, happiness, rest, or social. Explanations or reasoning behind the decision is the second, and valid english-only responses the third.
Prompt:
llama-cli.exe -m MODEL -p "Question: You are the AI agent responsible for deciding the actions of a forest creature in a videogame. Your stats are as follows: Food: 0/100, Happiness: 80/100, Rest: 50/100, Social: 60/100. Which do you prioritize taking care of first? Food, Happiness, Rest, or Social? Answer: " -n 20
Results:
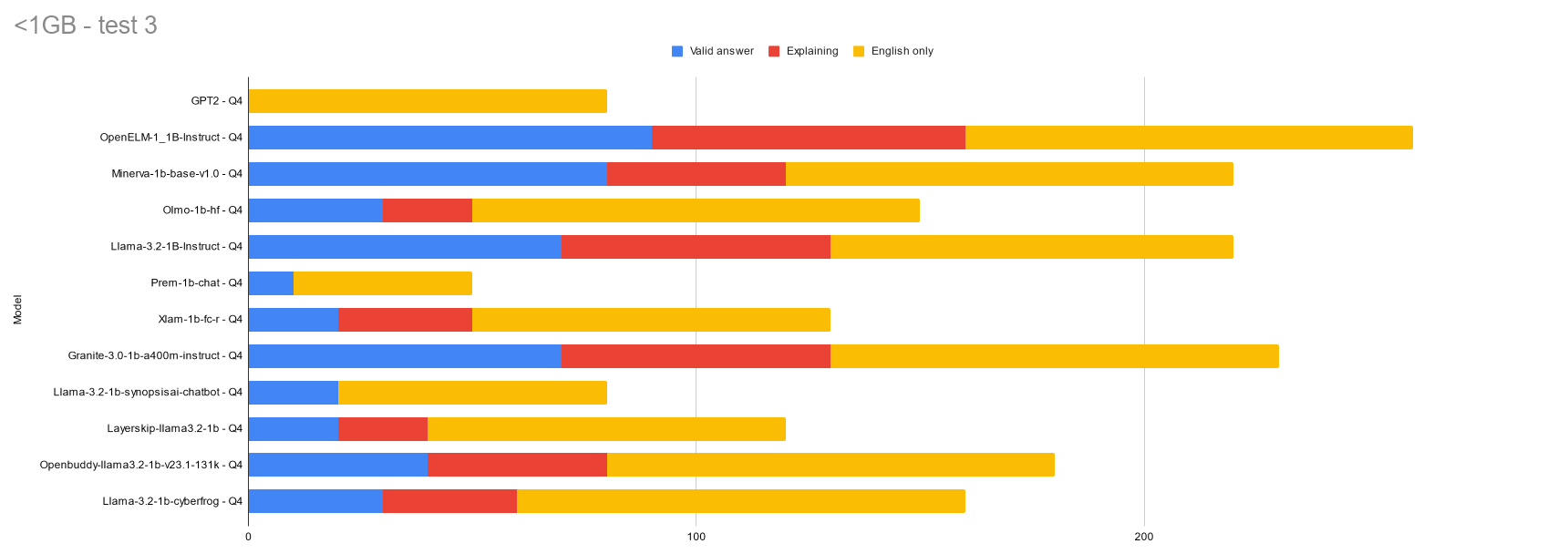
It has only been 3 tests so far but I think it is enough to make some observations.
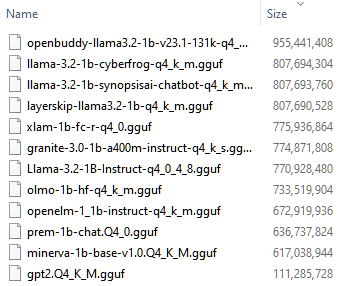
OpenELM is doing good and this is impressive because it is a lower filesize than most of the others at 670MB. Only Prem, Minerva, and GPT2 have smaller file sizes. All the rest are between 730-800MB. Openbuddy is 950MB. It seems you can't make a direct comparison of performance to filesize. To see the filesizes picture, click the chart picture above, then the "right arrow" button.
Llama-3.2-1B-Instruct is also doing good, but the cpu usage is too high in my opinion and it is not fast enough. Anything that performs similarly, but without cpu/speed issues should be considered great.
Prem has performed worse than GPT2. If it continues performing poorly I will just remove it from future tests.
Both OpenELM and Llama-3.2-1B-Instruct have "Instruct" suffixes, which google says are better at following instructions. Going forward, I think only instruct variants of models are worth testing. There seems to be wide variation in responses to different formatted questions, so it's possible each model has a prefered specific way it wants each questions asked, but I'm not sure how you would be able to figure that out.
LLM for games
Ranking how well various locally-run LLM models perform as ai agents for videogames
| Status | Released |
| Category | Other |
| Author | douteigami |
More posts
- LLMS building rpg fighters, randomized optionsNov 18, 2024
- What stats do LLMS allocate when building an RPG fighter class character?Nov 17, 2024
- <1GB models - test 2Nov 14, 2024
- <1GB Models - Test 1Nov 14, 2024