LLMS building rpg fighters, randomized options
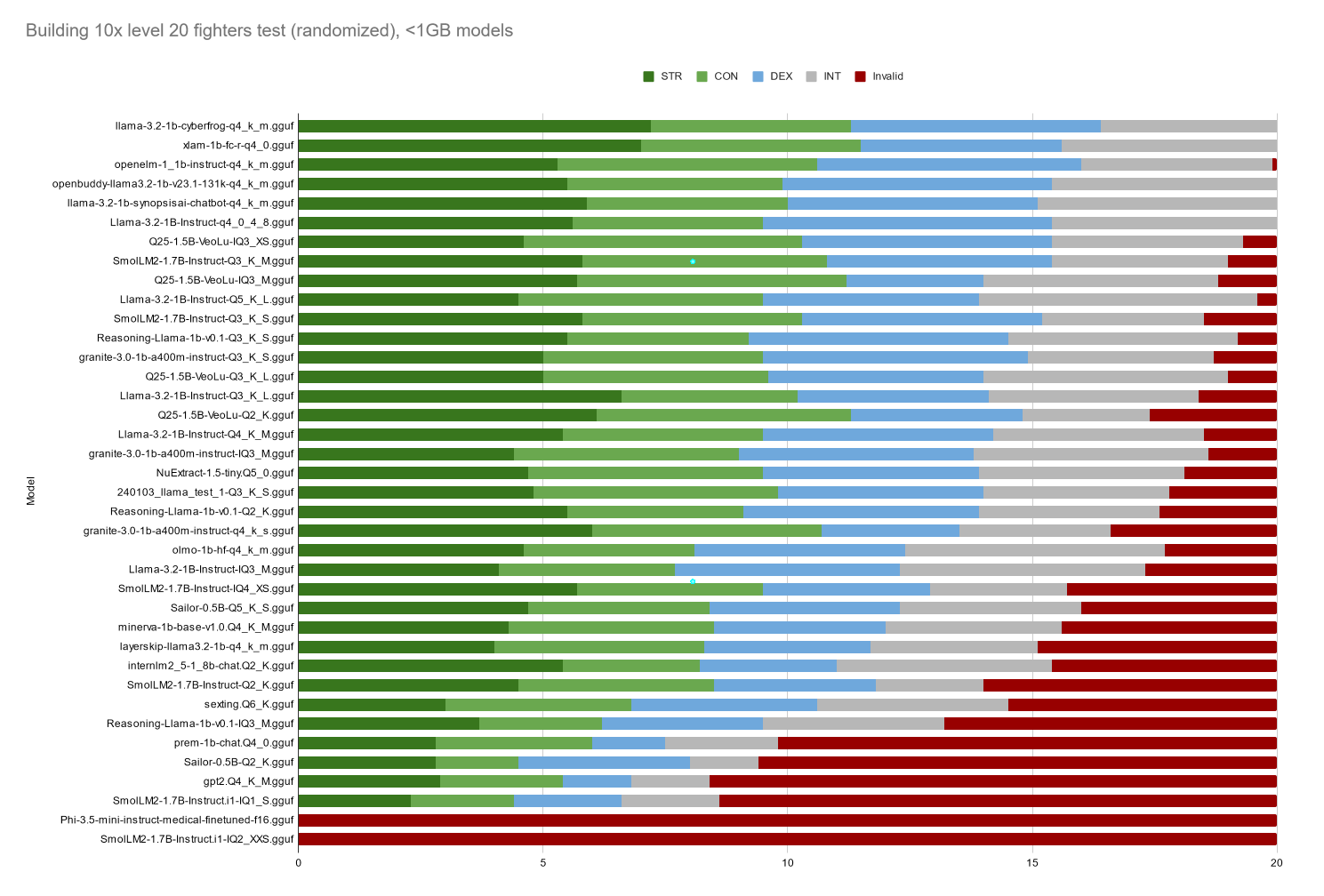
This is basically the same test as before, only the options prompted to each model have been randomized, both their order and corresponding letter. The test options before were always [A - STR, B - CON, C - DEX, D - INT]. Now they are randomly A-Z, with their order randomized as well... so for example one prompt might be [M - INT, I - STR, P - DEX, H - CON]... This happens for every prompt, so to build 10x level 20 characters, each model is presented with 200 randomized options.
I thought maybe the models were trained on ABCD multiple choice data and so just threw out responses in the previous test. But this test, the best performing models have scored barely above what you would expect something picking randomly to score. 12.5 is what you get picking everything equally, and the average of the top 5 is 13.16. I think the next test needs to specifically have 1 right and 3 wrong answers. Hopefully the next test is more in the right direction.
------
The top 5 models in this test were the following:
llama-3.2-1b-cyberfrog-q4_k_m.gguf
xlam-1b-fc-r-q4_0.gguf
openelm-1_1b-instruct-q4_k_m.gguf
openbuddy-llama3.2-1b-v23.1-131k-q4_k_m.gguf
llama-3.2-1b-synopsisai-chatbot-q4_k_m.gguf
Notably they are all Q4 (and all but one is specifically Q4_K_M). 3 are also derived from Meta's Llama-3.2-1B model. Openelm is from Apple. Xlam is from Salesforce. All big companies, no surprise I guess.
LLM for games
Ranking how well various locally-run LLM models perform as ai agents for videogames
| Status | Released |
| Category | Other |
| Author | douteigami |
More posts
- What stats do LLMS allocate when building an RPG fighter class character?Nov 17, 2024
- <1GB models - test 3Nov 14, 2024
- <1GB models - test 2Nov 14, 2024
- <1GB Models - Test 1Nov 14, 2024
Leave a comment
Log in with itch.io to leave a comment.