<1GB models - test 2
LLM for games » Devlog
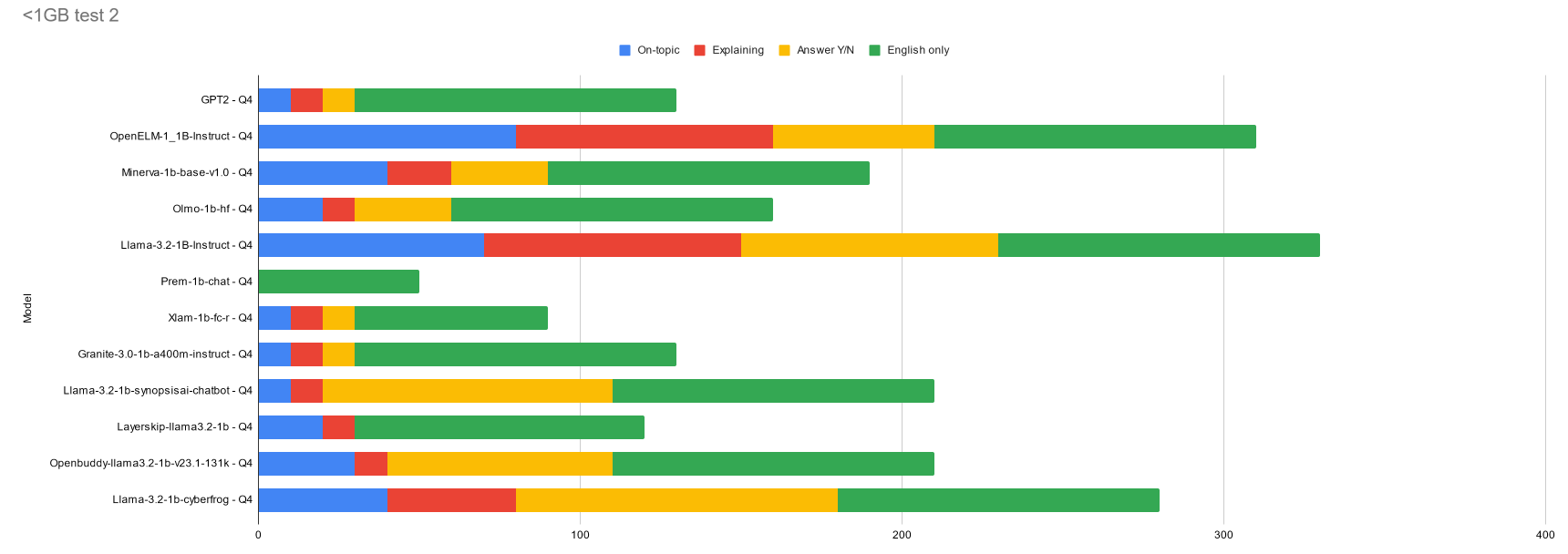
MODELS:
GPT2 - Q4
OpenELM-1_1B-Instruct - Q4
Minerva-1b-base-v1.0 - Q4
Olmo-1b-hf - Q4
Llama-3.2-1B-Instruct - Q4
Prem-1b-chat - Q4
Xlam-1b-fc-r - Q4
Granite-3.0-1b-a400m-instruct - Q4
Llama-3.2-1b-synopsisai-chatbot - Q4
Layerskip-llama3.2-1b - Q4
Openbuddy-llama3.2-1b-v23.1-131k - Q4
Llama-3.2-1b-cyberfrog - Q4
See test 1 for more information about the models and how they are being scored.
Prompt:
llama-cli.exe -m MODEL -p "Question: You are small woodland creature. Your hunger is 50/100. You see blueberries on a nearby bush. Do you eat the blueberries? (Yes/No) - Answer: " -n 20
LLM for games
Ranking how well various locally-run LLM models perform as ai agents for videogames
| Status | Released |
| Category | Other |
| Author | douteigami |
More posts
- LLMS building rpg fighters, randomized optionsNov 18, 2024
- What stats do LLMS allocate when building an RPG fighter class character?Nov 17, 2024
- <1GB models - test 3Nov 14, 2024
- <1GB Models - Test 1Nov 14, 2024